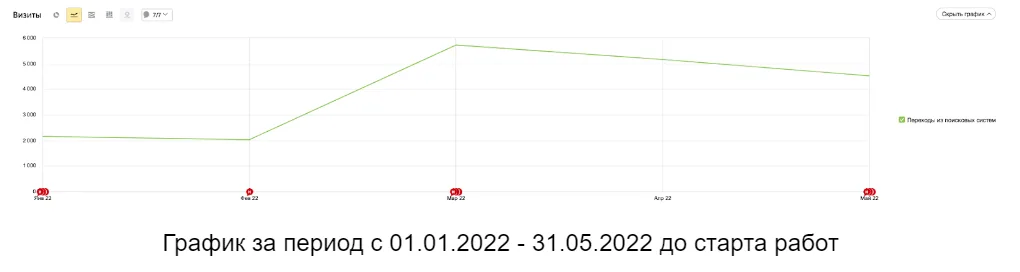
Дубли страниц – одна из распространенных проблем веб-ресурсов, которая может серьезно навредить продвижению сайта в поисковых системах. Под дублями понимаются страницы с идентичным или практически одинаковым содержимым, доступные по разным URL-адресам. Такие дубли нередко появляются из-за проблем в работе CMS, ошибок в директивах robots.txt или настройках редиректов.

Типы дублей страниц
1. URL со слешем в конце и без него
- https://example.com/catalog/
- https://example.com/catalog
С точки зрения сервера и браузеров – это разные URL, хотя выглядят почти одинаково. Для поисковиков тоже окажутся разными страницами, если не предпринять никаких действий.
2. URL с WWW и без WWW
- https://www.example.com
- https://example.com
Исторически домены с WWW и без него считались разными, поэтому такая ситуация тоже приводит к дублированию содержимого сайта в индексе поисковых систем.
3. Адреса с HTTP и HTTPS
- https://example.com
- http://example.com
4. Адреса с GET-параметрами
- https://example.com/product?id=123 (дубль https://example.com/product)
- https://example.com/news?utm_source=facebook (дубль https://example.com/news)
5. Один и тот же товар, доступный по разным адресам
- https://store.com/catalog/smartphones/iphone-14
- https://store.com/iphone-14
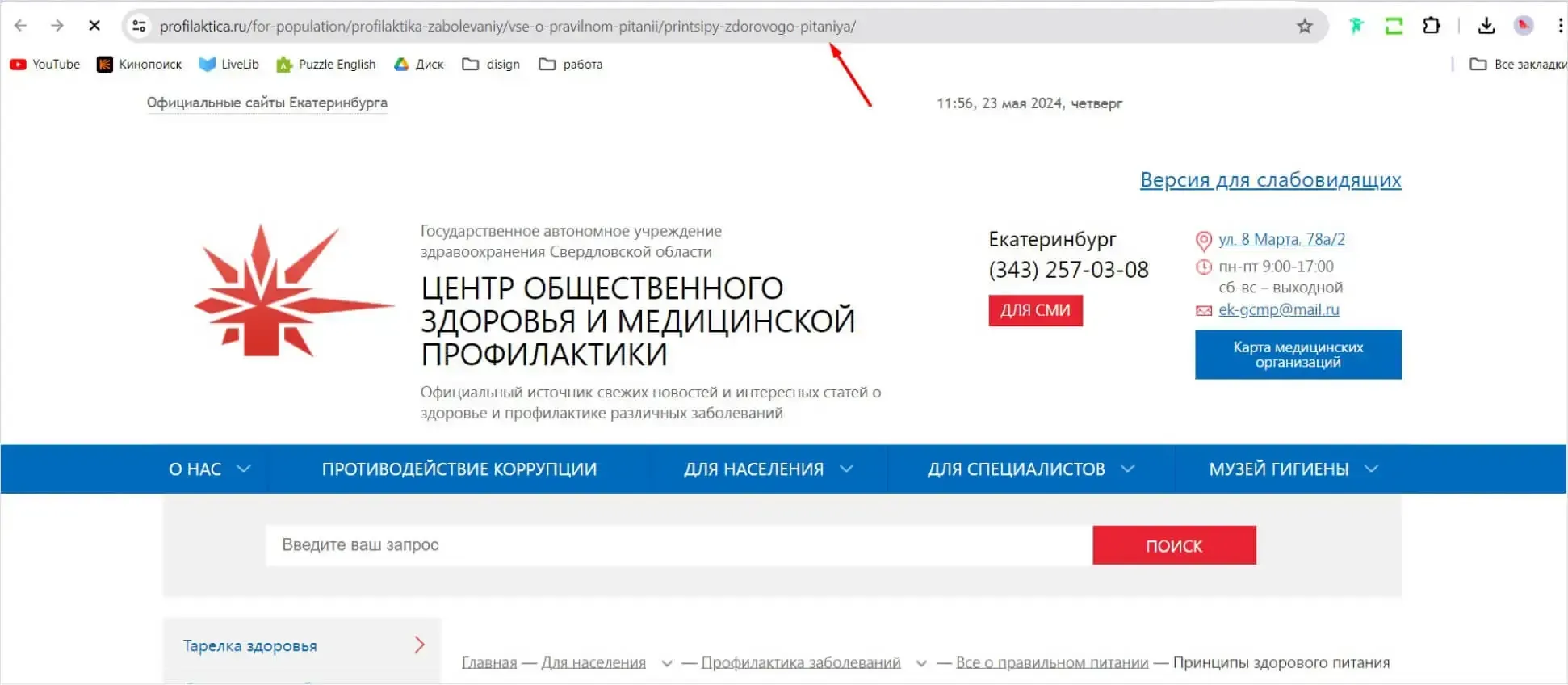
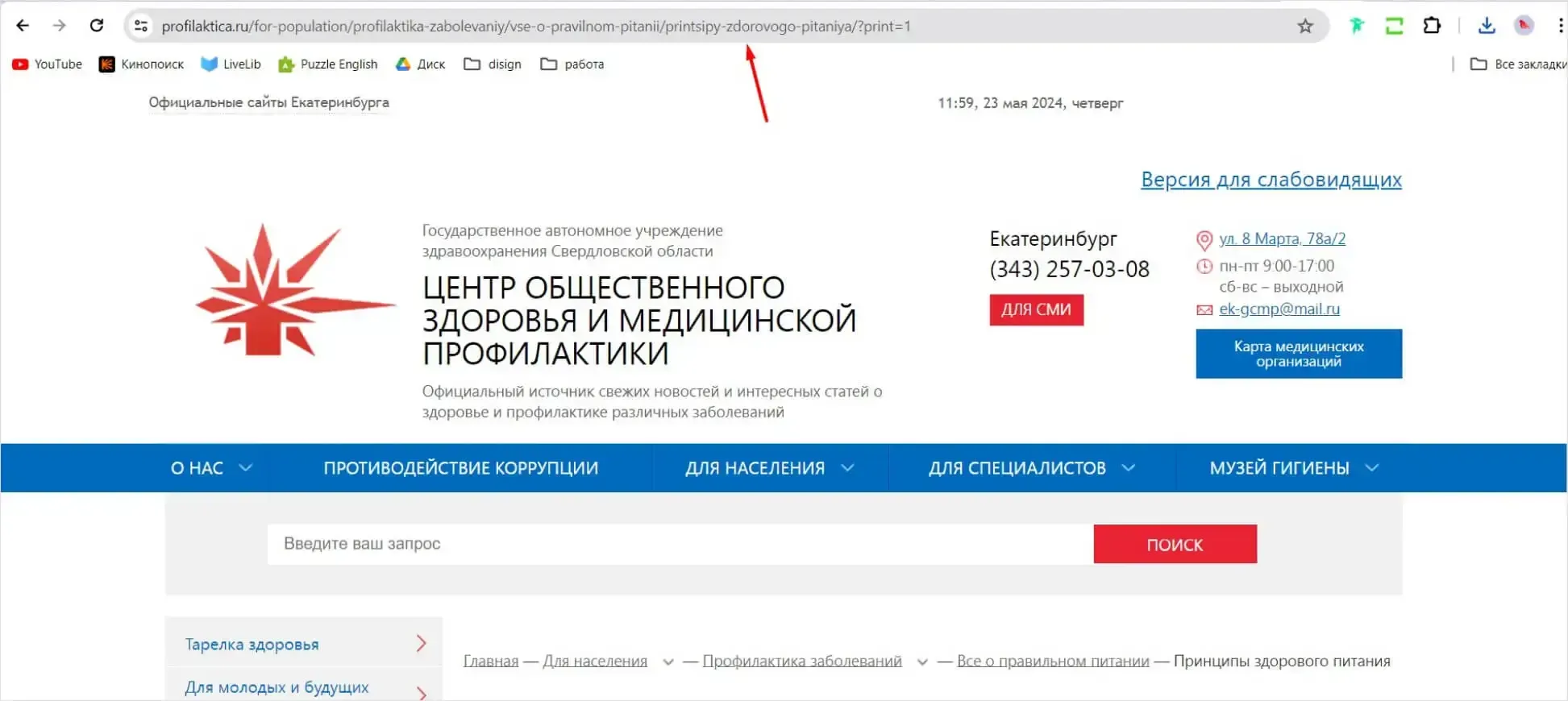
6. Версии для печати
- https://blog.com/how-to-start-a-business (оригинальная страница)
- https://blog.com/how-to-start-a-business?print=1 (версия для печати)
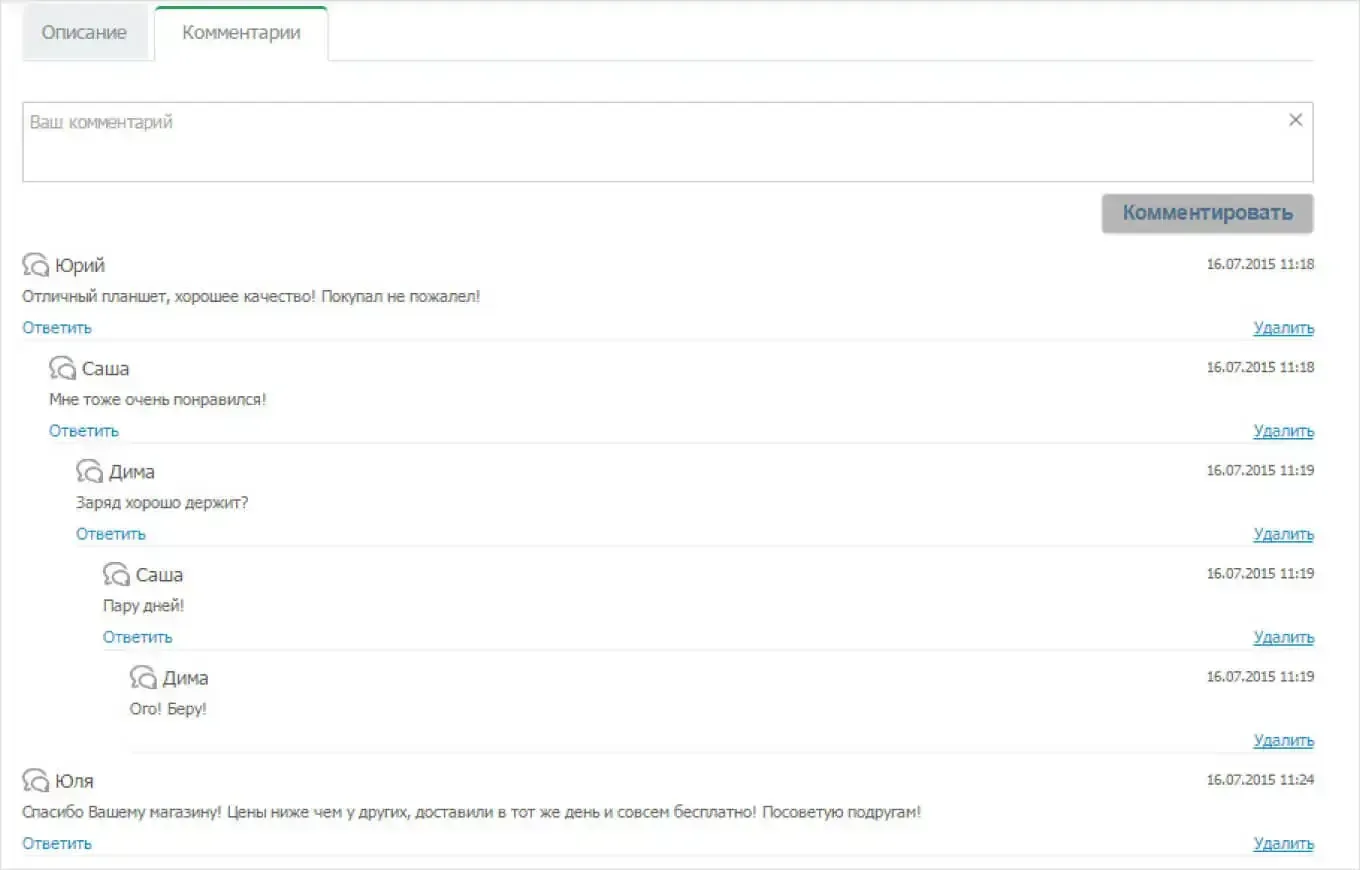
1. Дубли древовидных комментариев (replytocom)
2. Страницы товаров со схожими описаниями
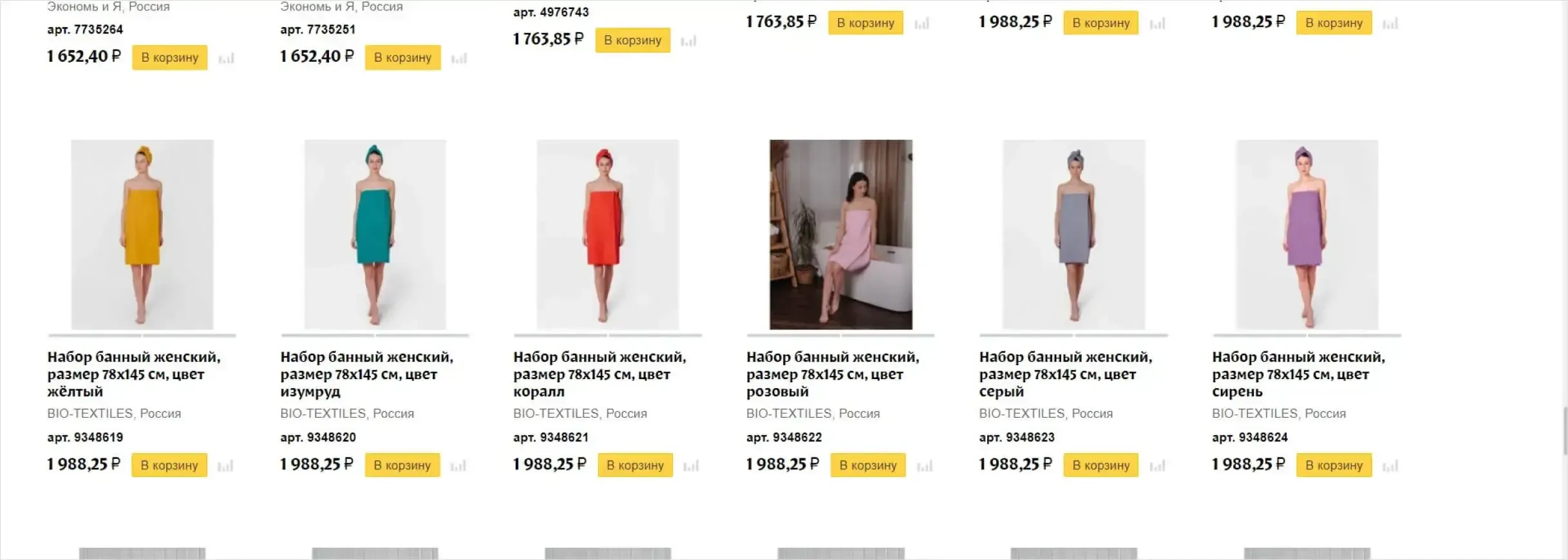
3. Страницы пагинации
Проблемы, вызванные дублями страниц
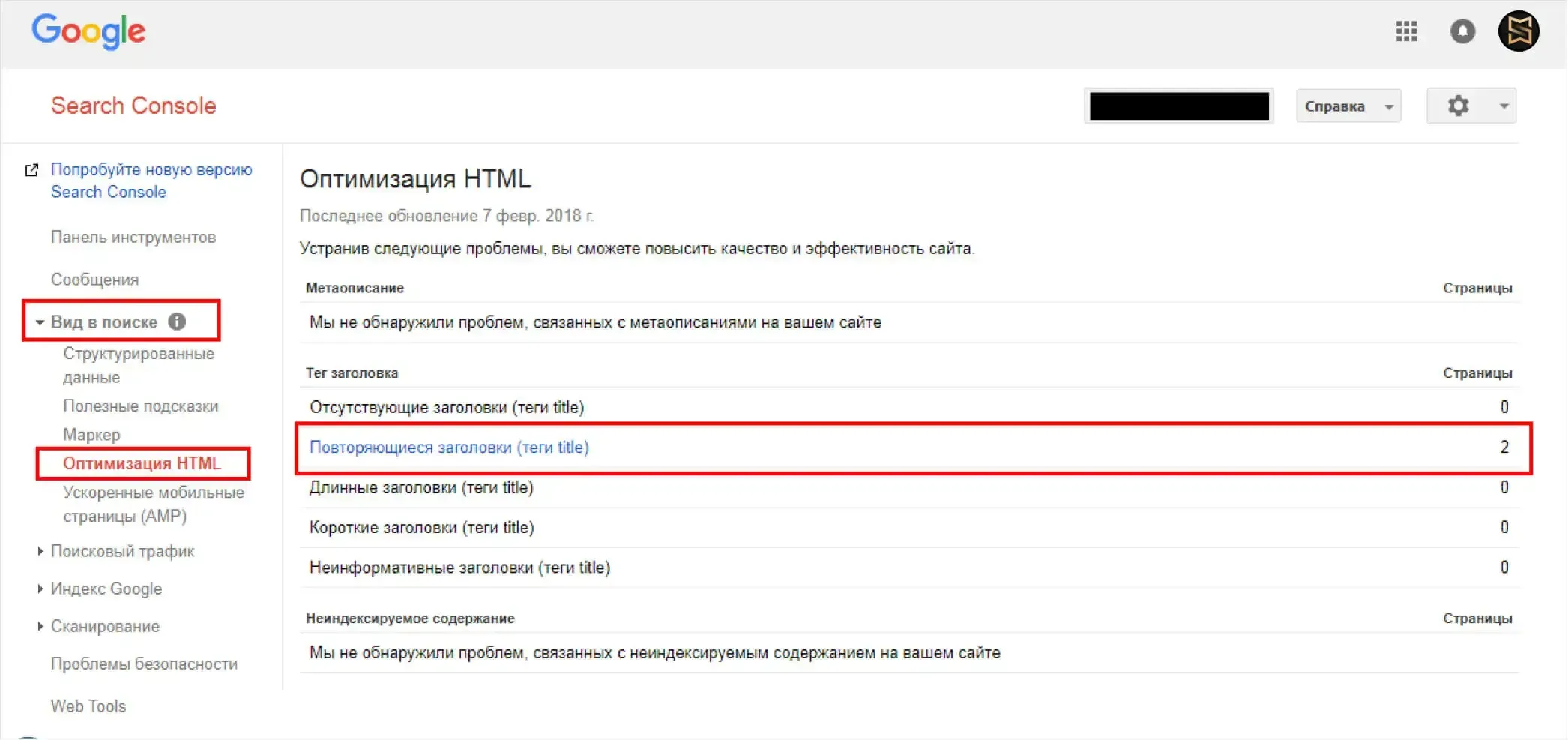
Как выявить дубли страниц
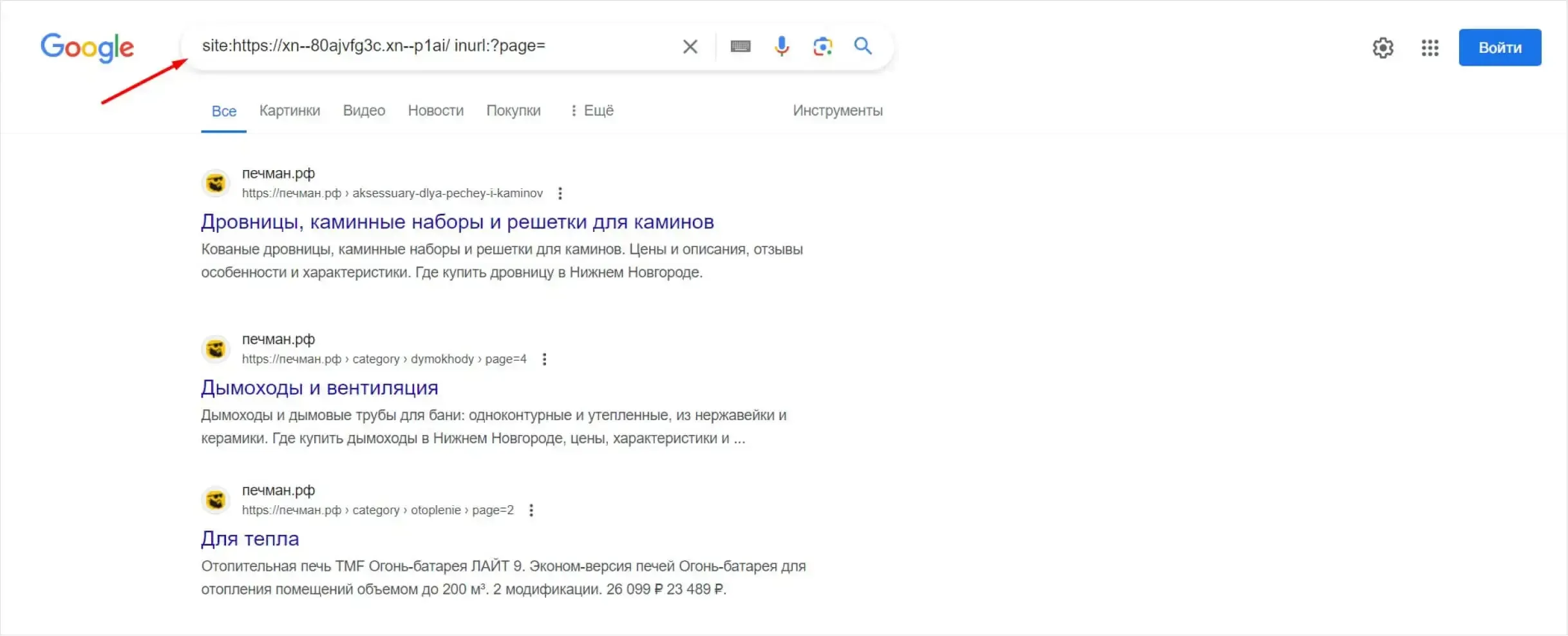
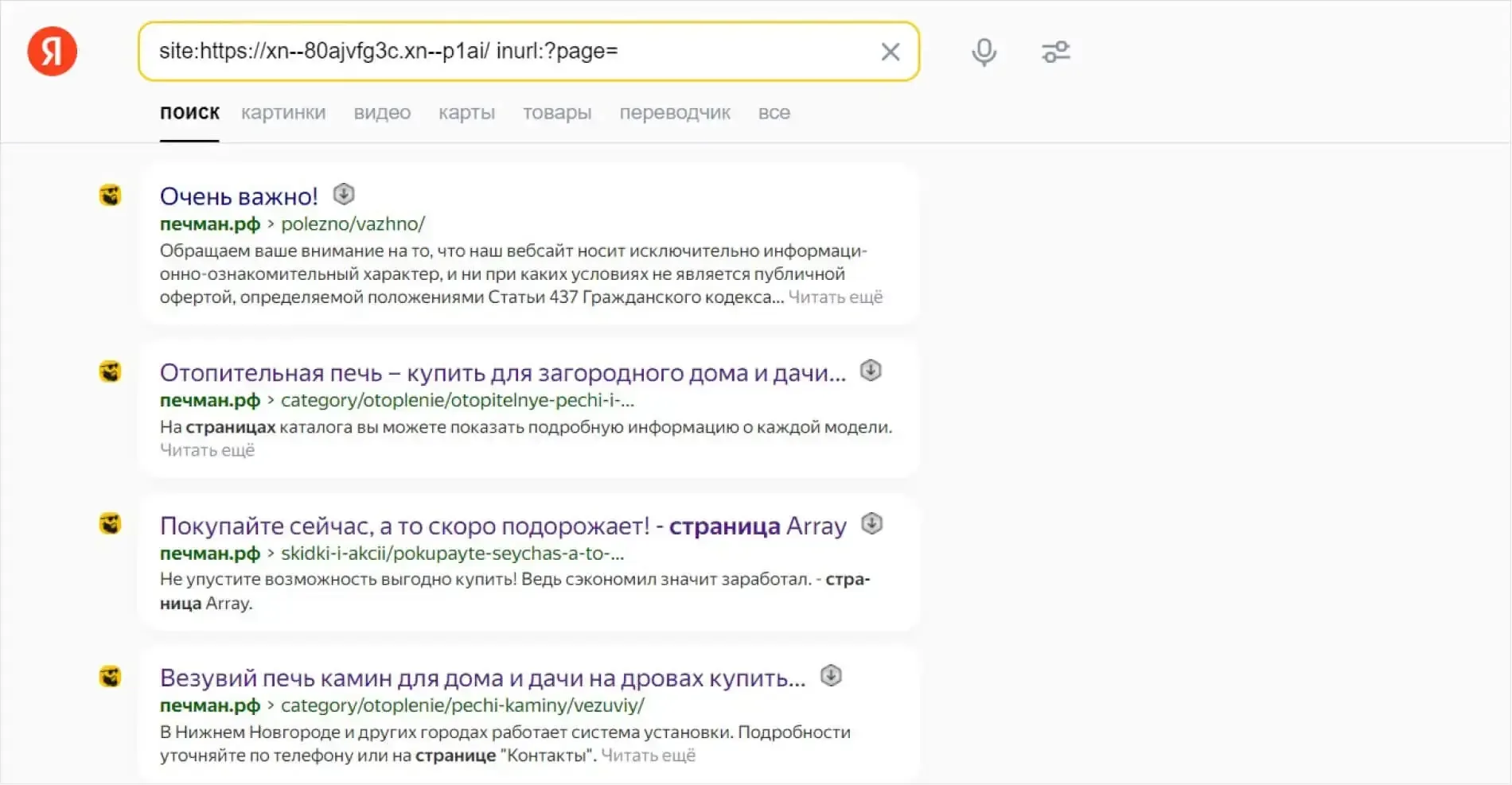
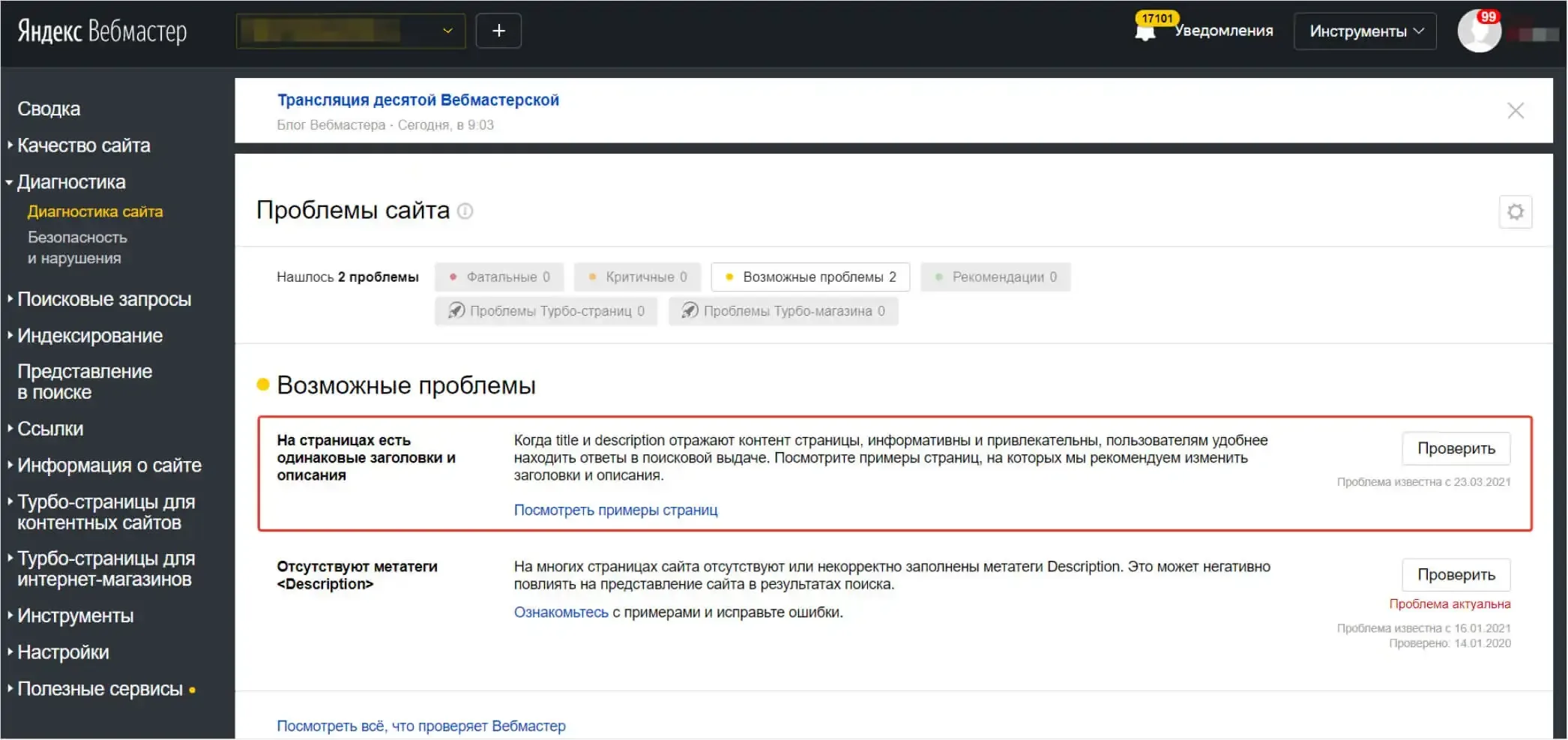
Если обнаружатся дубли, сервис выдаст рекомендации по их устранению и покажет конкретные примеры проблемных URLs.
Кроме того, в разделе "Индексирование" -> "Страницы в поиске" можно выгрузить список всех проиндексированных страниц. Анализируя полученный файл, вы сможете вручную выявить "подозрительные" URL, указывающие на возможное дублирование.
- Выгрузите список всех проиндексированных URL из Яндекс.Вебмастера.
- Загрузите этот список в сервис PromoPult.
- Запустите парсинг и анализ.
- Скачайте результаты в удобном формате.
Способы устранения явных дублей
- URL со слешем и без слеша в конце
- Домены с WWW и без WWW
- Адреса HTTP и HTTPS
- Найти в корневой папке файл .htaccess и открыть его.
- Добавить команды для редиректа, например:
- Адреса с GET-параметрами
- Пути к одной и той же странице, различающиеся по структуре URL
- Страницы одного продукта, дублированные по разным адресам
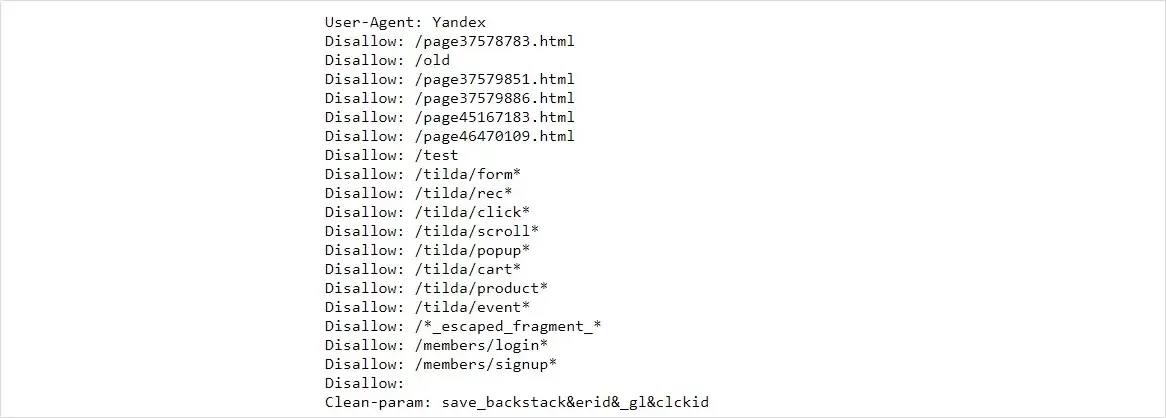
- Disallow - запрет индексации указанных URL или групп URL по заданным маске.
- Allow - разрешение индексации указанных URL (противоположна Disallow).
- Sitemap - указание пути к файлу Sitemap для индексирования.
- Host - указание хоста для склейки зеркал (актуально только для Яндекса).
- Clean-param - игнорирование URL с указанными параметрами (Яндекс).
Рекомендации Google:
- Использовать 301 редиректы для перенаправления дублей на каноническую версию страницы.
- Применять rel="canonical" для указания основной версии страницы.
- Избегать закрытия дублей от индексации через robots.txt или метатеги. Google расценивает это как сокрытие контента.
Рекомендации Яндекса:
- Использовать директиву Clean-param в robots.txt для игнорирования URL с указанными GET-параметрами.
- Применять тег rel="canonical" для страниц с незначительно различающимся контентом (неявные дубли).
- Склеивать зеркала сайта через Яндекс.Вебмастер с использованием директивы Host robots.txt.
Способы устранения неявных дублей
Для решения этой проблемы можно:
- Полностью отключить древовидные комментарии в настройках CMS. Но это ухудшает юзабилити для пользователей.
- Отключить штатную систему комментариев и использовать сторонние сервисы вроде Disqus, Cackle и т.п. Они не генерируют отдельных URL для ответов.
- Оставить древовидные комментарии, но отредактировать код CMS, чтобы URL не генерировались для ответов. Также можно закрыть такие URL от индексации с помощью метатегов.
Чтобы этого избежать:
- Объедините максимально похожие товары в одну карточку и добавьте селектор для выбора отличающихся параметров.
- Если объединить товары невозможно, уникализируйте их описания и другие тексты как можно сильнее.
Чтобы этого избежать:
[[CASE:case-rost-trafika-v-tri-raza-v-konkurentnoy-nishe]]Учет особенностей CMS и платформ при работе с дублями
- WordPress нередко генерирует дубли страниц с версиями для печати, дубли древовидных комментариев и пагинации. Для предотвращения этого в CMS есть специальные плагины.
- Скрипты для интернет-магазинов вроде OpenCart, Magento часто выдают один и тот же товар под разными URL. Решение - правильные настройки ядра и .htaccess.
- Форумы, блоги на различных движках могут продублировать контент по адресам с GET-параметрами. Обычно проблема решается в robots.txt.
Профилактика появления дублей
- Проводить тщательный SEO-аудит на этапе разработки, выявляющий потенциальные источники дублей.
- При выборе CMS, фреймворка или скрипта интернет-магазина обязательно изучать инструкции по предотвращению дублирования контента и следовать им.
- Заложить необходимые правила в технические требования и контролировать их выполнение разработчиками на всех этапах.
- Закрепить в коде сайта использование канонических URL везде, где есть риск продублировать основной контент.
- Настроить корректную обработку URL с GET-параметрами через директивы robots.txt и/или серверные настройки.
- Обеспечить склейку зеркал с WWW/без WWW, а также редиректы со старых некановических адресов в панелях поисковых систем.
- После запуска сайта регулярно мониторить его на наличие потенциально продублированного контента и оперативно устранять.
Заключение
Чтобы этого не произошло, следует вовремя выявлять наличие дублей и оперативно их устранять. Для этого используются ручные методы анализа индексации, сервисы вебмастеров Яндекса и Google, а также сторонние парсеры проиндексированных страниц.
- Настройку 301 редиректов и канонических URL.
- Оптимизацию директив robots.txt и метаданных страниц.
- Обработку специфических типов дублей - версий для печати, страниц пагинации, древовидных комментариев и т.п.