Приветствую вас, друзья!
Сегодня мы продолжим говорить на эту тему, но рассмотрим ее с точки зрения управления процессом индексирования, а именно: как разрешить или запретить попадание в индекс определенных страниц.

Для лучшего понимания ситуации, стоит обратиться к истории:
в прошлом, когда поисковые системы только начинали развиваться и значительно отличались от современных, поисковые роботы автоматически сканировали все доступные страницы сайтов. В результате в индекс попадала служебная информация, личные данные и другие ненужные материалы, которые не должны отображаться в поисковой выдаче. Неконтролируемая индексация всего подряд приводила к нерелевантным результатам поиска, что снижало эффективность поисковой системы.
Нужно было каким-то образом повлиять на этот процесс и “подсказать” роботам, какие страницы не нужно индексировать. Для этих целей и был придуман файл robots.txt.
Что такое robots.txt?
Когда краулер хочет просканировать сайт, он сначала отправляет запрос на сервер сайта, чтобы получить robots.txt. Файл роботс должен находиться в корневой папке вашего веб-сайта (обычно по адресу https://www.example.com/robots.txt) и быть общедоступным для чтения роботами ПС.
По умолчанию поисковые системы полагают, что могут сканировать и индексировать абсолютно любую страницу на вашем сайте, если это не запрещено специальной директивой в robots.txt.
В случае, если вам есть что, “прятать” от индексации на вашем сайте - robots.txt вам просто необходим.
Здесь также хочу отметить, что не всегда краулеры следуют инструкциям в файле. Роботы Яндекса и Гугла придерживаются указаний в директивах, но роботы других ПС могут их игнорировать.
Создание файла роботс не требует особых знаний или навыков. Вам просто нужно создать текстовый файл с именем robots.txt и сохранить его в корневой директории вашего сайта. Вы можете использовать любой текстовый редактор, такой как Notepad++ и другие подобные ему.
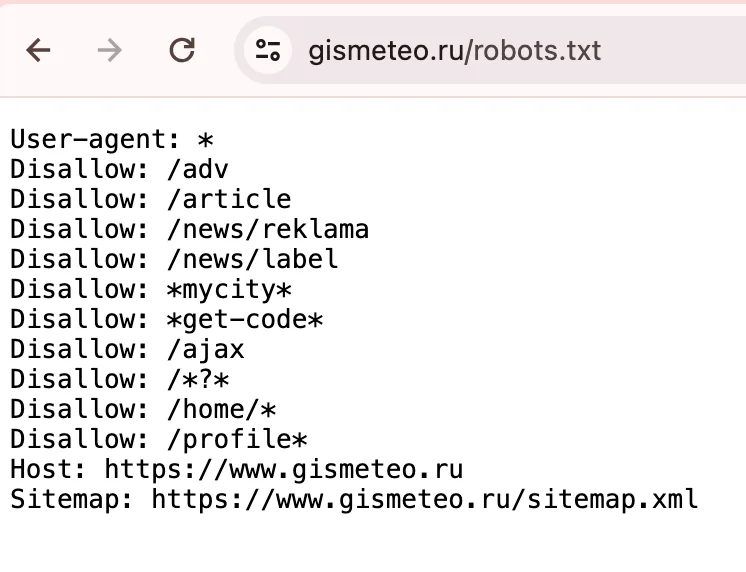
Рассмотрим основные директивы файла robots.txt и какие функции они выполняют:

User-agent имеет следующий синтаксис:
User-agent: Имя_робота
Имя_робота – это строка, которая идентифицирует робота поисковой системы.
Для каждой поисковой системы есть собственное имя робота:
Yandex - для Яндекса,
Googlbot - для Google,
* - для всех роботов
Для того, чтобы роботам было понятно, какие директивы выполнять при индексации обязательно соблюдайте следующие правила:
Используйте только необходимые директивы User-agent.
Обязательно проверяйте правильность написания имени робота. Не используйте кириллицу
Не оставляйте пустых строк.

Директивы allow и disallow
Синтаксис:
Allow: Путь_к_странице/разделу
Примеры:
Allow: / - разрешает индексацию главной страницы
Allow: /category/* - разрешает индексацию всех страниц в категории /category/
Allow: /product/1234 - разрешает индексацию страницы /product/1234
Синтаксис:
Disallow: Путь_к_странице/разделу
Примеры:
Disallow: /admin/* - запрещает индексацию всех страниц в папке /admin/
Disallow: /image.jpg - запрещает индексацию изображения image.jpg
Disallow: /*.php$ - запрещает индексацию всех файлов с расширением .php
Файл robots.txt служит не только для управления индексацией отдельных страниц, но и для того, чтобы указать поисковым системам расположение вашей карты сайта sitemap.xml.
Карта сайта – это файл, содержащий список всех страниц вашего сайта, которые вы хотите, чтобы поисковые системы проиндексировали.
Ускорение индексации: ПС могут быстрее обнаружить новые и обновленные страницы вашего сайта, если вы укажете ссылку на карту сайта в robots.txt.
Улучшение понимания структуры сайта: Карта сайта помогает ПС понять структуру вашего сайта и взаимосвязь между страницами.
Больший контроль: Информируя ПС о наличии карты сайта, вы получаете больший контроль над тем, какие страницы они видят и индексируют.
Как указать sitemap в robots.txt
Для того, чтобы указать ссылку на карту сайта в robots.txt, используйте следующую директиву:
Sitemap: https://www.example.com/sitemap.xml
Если у вас есть несколько карт сайта для разных разделов вашего сайта, вы можете указать их все в robots.txt с помощью отдельной директивы Sitemap для каждой карты:
Sitemap: https://www.example.com/sitemap-posts.xml
Sitemap: https://www.example.com/sitemap-products.xml
Убедитесь, что ваша карта сайта корректна и обновлена.
Размещайте директиву Sitemap в конце файла robots.txt.
Можно указать несколько карт сайта.
Проверяйте файл robots.txt с помощью инструментов Google Search Console, чтобы убедиться, что ПС обнаружили вашу карту сайта.
Устранение дублей контента: Страницы с одинаковым контентом, но разными значениями динамических параметров, могут рассматриваться ПС как дубли. Clean-param помогает этого избежать
Оптимизация краулингового бюджета: ПС не будут тратить ресурсы на сканирование страниц с разными значениями динамических параметров, если их содержание одинаково.
Более точная индексация: Указание Clean-param позволяет ПС точнее понять структуру вашего сайта и контент страниц
Имя_параметра – это название динамического параметра в URL-адресе (например, session_id, sort, utm_source)
Вы можете указать несколько параметров, разделяя их символом &.
Сlean-param поддерживается не всеми ПС, в основном Яндексом
Необходимо указывать все динамические параметры, которые не влияют на контент.
Неправильное использование Clean-param может привести к нежелательным последствиям, таким как пропущенные страницы.
В целом, Clean-param является полезным инструментом для оптимизации индексации вашего сайта в Яндексе, особенно если вы используете динамические параметры в URL-адресах.

Хотя файл robots.txt сам по себе не имеет явной системы приоритетов, вы можете косвенно влиять на то, как поисковые роботы сканируют ваш сайт и какие страницы индексируют, используя несколько приемов:
Разделяйте роботов ПС на группы и для каждой группы указывайте свои правила индексации. Для более важных групп роботов (например, Googlebot) ставьте их выше в файле robots.txt.
Пример:
User-agent: Googlebot
Allow: /
Allow: /category/*
Allow: /product/*
User-agent: Yandex
Allow: /
Disallow: /category/*
Пример:
Disallow: /
Allow: /category/*
Allow: /product/*
В этом примере все страницы сайта запрещены к индексации (Disallow: /), за исключением страниц в категориях (Allow: /category/*) и страниц товаров (Allow: /product/*).
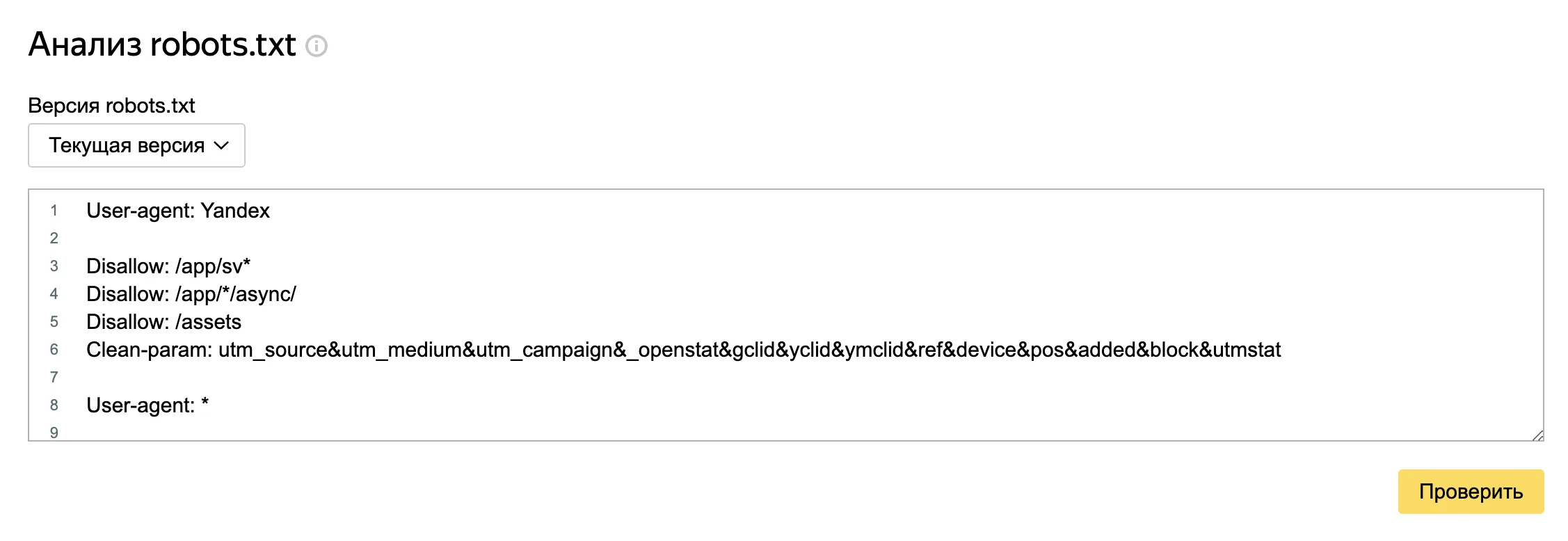
1. Найти инструмент:
- Авторизуйтесь в Яндекс Вебмастере.
- Выберите нужный сайт.
- В меню слева перейдите в раздел "Инструменты".
- Выберите "Анализ robots.txt".

2. Провести анализ:
- В поле "Введите robots.txt" вставьте содержимое вашего файла robots.txt.
- Нажмите "Проверить".
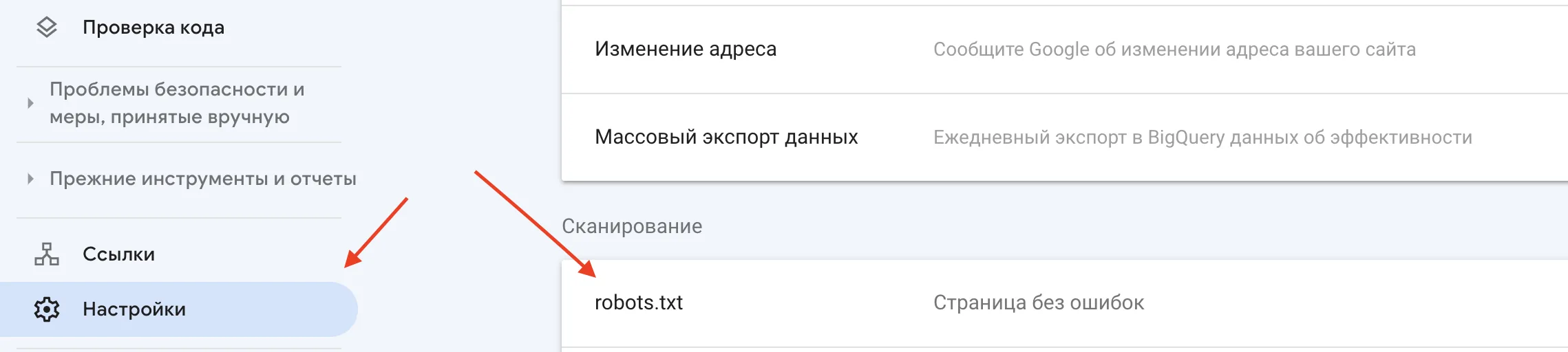
1. Найти инструмент:
- Авторизуйтесь в Google Search Console.
- Выберите нужный сайт.
- В меню слева перейдите в раздел "Настройки".
- Выберите "Проверка robots.txt".
2. Провести анализ:
- Google Search Console автоматически проверит ваш файл robots.txt.
- Если обнаружены ошибки, они будут отображены на странице.
Общие рекомендации по настройке robots.txt
Ниже я привел общепринятые рекомендации по настройке robots.txt для обеспечения корректной индексации вашего сайта:
Используйте только необходимые директивы.
Используйте правильный синтаксис для каждой директивы.
Не оставляйте пустых строк.
Используйте отступы для лучшей читаемости.
Добавьте комментарии для пояснения ваших действий.
Регулярно обновляйте robots.txt при изменениях на вашем сайте.
Используйте инструменты Яндекс Вебмастер и Google Search Console для проверки корректности robots.txt.
Используйте Clean-param для управления динамическими параметрами URL-адреса.
Robots.txt – это не просто инструмент для исключения страниц из индексации. Он позволяет вам управлять процессом индексирования.
Корректная настройка файла robots.txt играет важную роль в SEO и общем функционировании вашего сайта. При его создании и редактировании важно учитывать требования поисковых систем и цели вашего сайта, чтобы получить максимальную отдачу от этого инструмента.
Надеюсь, что данная статья поможет вам правильно настроить robots.txt для вашего сайта!
[[CTA:audit]]



